DS:《What Are the Data-Centric AI Concepts behind GPT Models?通过三个数据为中心的人工智能目标(训练数据开发、推理数据开发和数据维护)揭示GPT模型背后的数据为中心的人工智能概念》解读—GPT-1/GPT-2/GPT-3系列对比(语料大小+参数量+解码层数+上下文长度+隐藏层大小)
导读
:文章分析了GPT模型代表的大语言模型最新发展,强调了Data-Centric AI 概念在其成功中的重要作用。Data-Centric AI将变得更加关键,而语言模型将有助于实现更高效的数据中心AI。GPT模型代表大语言模型最新进展,能够完成诸如翻译、自动总结等任务。它成功
得益于大量高质量的数据训练
。GPT-3模型使用了570GB的数据,只选取了总数据的1.27%。
Data-Centric AI 强调着力于改善构建AI所使用的数据质量和量
。重视数据本身,模型相对固定。它有三大目标:训练数据开发,推理数据开发和数据维护。Data-Centric AI 将变得更重要。调参已成熟,唯一提升AI能力的方式是优化数据
。
GPT模型成功离不开Data-Centric AI 策略
:使用了大量高质量的数据进行训练;使用人类标注来微调和优化GPT模型;使用调参(prompts)来引导GPT输出;ChatGPT可能不断收集用户反馈来持续进化
。
LLM的成功革新了AI,并将进一步改变数据科学的生命周期
。Data-Centric AI 变得更加重要,通过工程化数据
来改进AI系统。LLM能够帮助提高Data-Centric AI 解决方案的效率,如自动处理和清洗数据、生成数据集。
目录
《What Are the Data-Centric AI Concepts behind GPT Models?》翻译与解读
LLMs的成功主要归功于大量和高质量的训练数据、以GPT为例引出数据中心AI的三个目标=训练数据开发+推理数据开发+数据维护
GPT-1/GPT-2/GPT-3系列对比(语料大小+参数量+解码层数+上下文长度+隐藏层大小)
GPT系列模型基于类似的模型架构:4.8GB(未过滤)数据【GPT-1】→40GB人工过滤数据【GPT-3】→从45TB原始数据中过滤得到570GB数据【GPT-3】→人类示范和注解【GPT-4】
GPT系列模型(GPT-1、GPT-2、GPT-3)的模型尺寸比较:参数量、解码层数、上下文长度、隐藏层大小
大型语言模型(llm)和GPT模型—GPT模型的架构主要基于Transformer+使用文本和位置嵌入作为输入+使用注意力层来建模标记之间的关系、后续的GPT模型=更多的模型参数+更多的层+更大的上下文长度+更大隐藏层大小
什么是数据为中心的人工智能?—三目标(训练数据开发/推理数据开发/数据维护)、相对于模型中心AI,数据中心AI能更有效地提高模型效能
为什么以数据为中心的人工智能使GPT模型成功—关键在于不断改进的数据集和数据策略
GPT-2使用更高质量的数据集+数据过滤和清洗策略、GPT-3使用了更多更高质量的数据集+人工分类和数据去重、InstructGPT采用人类标注来微调GPT-3、ChatGPT/GPT-4广泛使用RLHF来微调模型进一步提高数据量和质量+通过不断收集用户反馈来持续优化
提示调优
基于软提示的校准
数据科学社区可以从这一波LLM(语言模型)中学到什么?——工程化数据将成为改进LLM的关键、LLM将实现更好的数据中心的AI解决方案
用LLM生成合成数据来训练模型
Resources
《What Are the Data-Centric AI Concepts behind GPT Models?》翻译与解读
| 地址 | https://towardsdatascience.com/what-are-the-data-centric-ai-concepts-behind-gpt-models-a590071bb727 |
|---|---|
| 时间 | 2023年3月29日 |
| 作者 | Henry Lai |
LLMs的成功主要归功于大量和高质量的训练数据、以GPT为例引出数据中心AI的三个目标=训练数据开发+推理数据开发+数据维护
GPT-1/GPT-2/GPT-3系列对比(语料大小+参数量+解码层数+上下文长度+隐藏层大小)
GPT系列模型基于类似的模型架构:4.8GB(未过滤)数据【GPT-1】→40GB人工过滤数据【GPT-3】→从45TB原始数据中过滤得到570GB数据【GPT-3】→人类示范和注解【GPT-4】
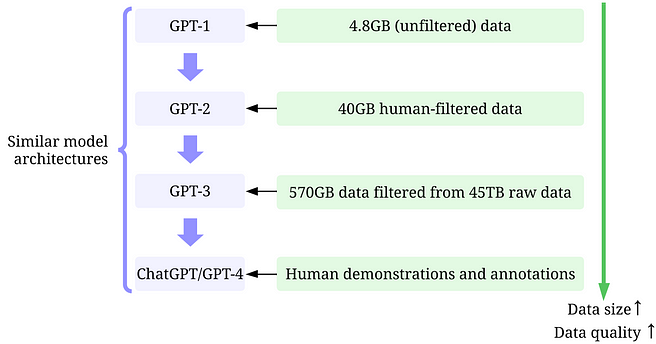
GPT系列模型(GPT-1、GPT-2、GPT-3)的模型尺寸比较:参数量、解码层数、上下文长度、隐藏层大小
1.17亿、15亿、1750亿

图片:GPT系列模型的模型尺寸比较。
| Artificial Intelligence (AI) has made incredible strides in transforming the way we live, work, and interact with technology. Recently, that one area that has seen significant progress is the development of Large Language Models (LLMs), such as GPT-3, ChatGPT, and GPT-4. These models are capable of performing tasks such as language translation, text summarization, and question-answering with impressive accuracy. While it’s difficult to ignore the increasing model size of LLMs, it’s also important to recognize that their success is due largely to the large amount and high-quality data used to train them. In this article, we will present an overview of the recent advancements in LLMs from a data-centric AI perspective, drawing upon insights from our recent survey papers [1,2] with corresponding technical resources on GitHub. Particularly, we will take a closer look at GPT models through the lens of data-centric AI, a growing concept in the data science community. We’ll unpack the data-centric AI concepts behind GPT models by discussing three data-centric AI goals: training data development, inference data development, and data maintenance. | 人工智能(Artificial Intelligence,AI)在改变我们的生活、工作和与技术互动方面取得了令人难以置信的进展。最近,其中一个取得显著进步的领域是大型语言模型(Large Language Models,LLMs)的发展,例如GPT-3、ChatGPT和GPT-4。这些 模型能够以令人印象深刻的准确度执行 语言翻译、文本摘要和问答等任务。 虽然很难忽视LLMs模型的日益增长的模型规模,但也很重要认识到它们的成功在 很大程度上归功于用于训练它们的大量高质量数据 。 在本文中,我们将从以数据为中心的人工智能角度概述LLMs的最新进展,结合我们最近在GitHub上的调研论文[1,2]和相应的技术资源进行讨论。特别是,我们将通过数据为中心的人工智能概念来更详细地探讨GPT模型,这是数据科学界中一个不断发展的概念。我们将通过讨论三个数据为中心的人工智能目标( 训练数据开发、推理数据开发和数据维护 ),揭示GPT模型背后的数据为中心的人工智能概念。 |
|---|
大型语言模型(llm)和GPT模型—GPT模型的架构主要基于Transformer+使用文本和位置嵌入作为输入+使用注意力层来建模标记之间的关系、后续的GPT模型=更多的模型参数+更多的层+更大的上下文长度+更大隐藏层大小
Large Language Models (LLMs) and GPT Models

图片:一个使用LLM预测上下文中丢失令牌的概率的说明性示例

图片:GPT-1模型架构,图片来自论文
| LLMs are a type of Natual Language Processing model that are trained to infer words within a context. For example, the most basic function of an LLM is to predict missing tokens given the context. To do this, LLMs are trained to predict the probability of each token candidate from massive data. GPT models refer to a series of LLMs created by OpenAI, such as GPT-1, GPT-2, GPT-3, InstructGPT, and ChatGPT/GPT-4. Just like other LLMs, GPT models’ architectures are largely based on Transformers, which use text and positional embeddings as input, and attention layers to model tokens’ relationships. The later GPT models use similar architectures as GPT-1, except for using more model parameters with more layers, larger context length, hidden layer size, etc. | 大型语言模型(LLMs)和GPT模型 LLMs是一种自然语言处理模型,训练用于根 据上下文推断单词 。例如,LLMs最基本的功能之一是在给定上下文的情况下 预测缺失的标记 。为此,LLMs被训练以预测大量数据中每个标记候选的概率。 GPT模型是由OpenAI创建的一系列LLMs,例如GPT-1、GPT-2、GPT-3、InstructGPT以及ChatGPT/GPT-4。与其他LLMs一样,GPT模型的架构 主要基于Transformer ,使用 文本和位置嵌入作为输入 ,并使用 注意力层来建模标记之间的关系 。 后续的GPT模型采用与GPT-1类似的架构, 只是使用了更多的模型参数 、 更多的层 、 更长的上下文长度 和 更大的隐藏层尺寸 等。 |
|---|
什么是数据为中心的人工智能?—三目标(训练数据开发/推理数据开发/数据维护)、相对于模型中心AI,数据中心AI能更有效地提高模型效能
What is data-centric AI?
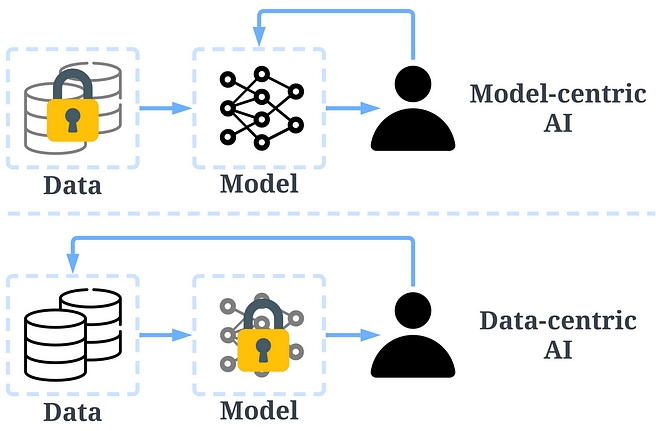
tu以数据为中心的AI和以模型为中心的AI的比较
| Data-centric AI is an emerging new way of thinking about how to build AI systems. It has been advocated by Andrew Ng, an AI pioneer. In the past, we mainly focused on creating better models with data largely unchanged (model-centric AI). However, this approach can lead to problems in the real world because it doesn’t consider the different problems that may arise in the data, such as inaccurate labels, duplicates, and biases. As a result, “overfitting” a dataset may not necessarily lead to better model behaviors. In contrast, data-centric AI focuses on improving the quality and quantity of data used to build AI systems. This means that the attention is on the data itself, and the models are relatively more fixed. Developing AI systems with a data-centric approach holds more potential in real-world scenarios, as the data used for training ultimately determines the maximum capability of a model. | 数据为中心的人工智能 是一种新兴的构建人工智能系统的思维方式。这一概念由人工智能先驱Andrew Ng提倡。 过去,我们主要关注通过数据的微小变化来创建更好的模型(以模型为中心的人工智能)。然而,这种方法在现实世界中可能会导致问题,因为它没有考虑到数据可能出现的不同问题,例如 不准确的标签、重复数据和偏见 。因此, “过拟合”数据集不一定会导致模型行为更好 。 相反,数据为中心的人工智能 侧重于改进 用于构建人工智能系统的 数据的质量和数量 。这意味着关注的 焦点在于数据本身 ,而模型相对固定。通过以数据为中心的方法开发人工智能系统,在真实世界的场景中具有更大的潜力,因为 用于训练的数据最终决定了模型的最大能力 。 |
|---|---|
| It is important to note that “data-centric” differs fundamentally from “data-driven”, as the latter only emphasizes the use of data to guide AI development, which typically still centers on developing models rather than engineering data. The data-centric AI framework consists of three goals: Training data development is to collect and produce rich and high-quality data to support the training of machine learning models. Inference data development is to create novel evaluation sets that can provide more granular insights into the model or trigger a specific capability of the model with engineered data inputs. Data maintenance is to ensure the quality and reliability of data in a dynamic environment. Data maintenance is critical as data in the real world is not created once but rather necessitates continuous maintenance. | 需要注意的是,“ 数据为中心 ”与“ 数据驱动 ”有根本的不同,后者只强调使用数据指导人工智能发展,通常仍 以开发模型为中心 ,而不是工程化数据。 数据为中心的人工智能框架包括三个目标: 训练数据 开发旨在收集和生成 丰富且高质量 的数据,以支持机器学习模型的训练。 推理数据 开发旨在创建新颖的评估集,以提供对模型更详细的洞察或触发模型特定能力的 工程化数据输入 。 数据维护 旨在确保在动态环境中数据的质量和可靠性。数据维护至关重要,因为真实世界中的数据不是一次性创建的,而是需要 持续维护 的。 |
为什么以数据为中心的人工智能使GPT模型成功—
关键在于不断改进的数据集和数据策略
Why Data-centric AI Made GPT Models Successful
GPT-2使用更高质量的数据集+数据过滤和清洗策略、GPT-3使用了更多更高质量的数据集+人工分类和数据去重、InstructGPT采用人类标注来微调GPT-3、ChatGPT/GPT-4广泛使用RLHF来微调模型进一步提高数据量和质量+通过不断收集用户反馈来持续优化
| Months earlier, Yann LeCun tweeted that ChatGPT was nothing new. Indeed, all techniques (transformer, reinforcement learning from human feedback, etc.) used in ChatGPT and GPT-4 are not new at all. However, they did achieve incredible results that previous models couldn’t. So, what is the driving force of their success? Training data development. The quantity and quality of the data used for training GPT models have seen a significant increase through better data collection, data labeling, and data preparation strategies. | 几个月前,Yann LeCun在推特上表示, ChatGPT并没有什么新东西 。确实,在ChatGPT和GPT-4中使用的所有技术(包括 Transformer、从人类反馈中进行强化学习 等)都并非新技术。然而,它们确实取得了之前的模型无法达到的惊人结果。那么,是 什么推动了它们的成功 呢? 训练数据开发 。通过 更好的数据 收集、数据标注和数据准备策略,用于训练GPT模型的数据的数量和质量有了显著提高。 |
|---|---|
| GPT-1: BooksCorpus dataset is used in training. This dataset contains 4629.00 MB of raw text, covering books from a range of genres such as Adventure, Fantasy, and Romance. - Data-centric AI strategies: None. - Result: Pertaining GPT-1 on this dataset can increase performances on downstream tasks with fine-tuning. GPT-2: WebText is used in training. This is an internal dataset in OpenAI created by scraping outbound links from Reddit. - Data-centric AI strategies: (1) Curate/filter data by only using the outbound links from Reddit, which received at least 3 karma. (2) Use tools Dragnet and Newspaper to extract clean contents. (3) Adopt de-duplication and some other heuristic-based cleaning (details not mentioned in the paper) - Result: 40 GB of text is obtained after filtering. GPT-2 achieves strong zero-shot results without fine-tuning. | GPT-1 :在训练中使用了BooksCorpus数据集。该数据集包含4629.00 MB的原始文本,涵盖了冒险、奇幻和浪漫等各种类型的图书。 数据为中心的人工智能策略 :无。 结果 :使用该数据集对GPT-1进行微调可以提高在下游任务上的性能。 GPT-2 :在训练中使用了WebText数据集。这是OpenAI内部通过从Reddit抓取出站链接创建的数据集。 数据为中心的人工智能策略 : (1)通过仅使用Reddit上至少获得3个赞的出站链接来筛选数据; (2)使用 Dragnet和Newspaper等工具提取干净 的内容; (3)采用 去重和其他一些基于启发式的清理 方法(论文中未详细说明)。 结果 :经过筛选后获得了40GB的文本。GPT-2在零样本情况下取得了 强大的结果,无需微调 。 |
| GPT-3: The training of GPT-3 is mainly based on Common Crawl. - Data-centric AI strategies: (1) Train a classifier to filter out low-quality documents based on the similarity of each document to WebText, a proxy for high-quality documents. (2) Use Spark’s MinHashLSH to fuzzily deduplicate documents. (3) Augment the data with WebText, books corpora, and Wikipedia. - Result: 570GB of text is obtained after filtering from 45TB of plaintext (only 1.27% of data is selected in this quality filtering). GPT-3 significantly outperforms GPT-2 in the zero-shot setting. InstructGPT: Let humans evaluate the answer to tune GPT-3 so that it can better align with human expectations. They have designed tests for annotators, and only those who can pass the tests are eligible to annotate. They have even designed a survey to ensure that the annotators enjoy the annotating process. - Data-centric AI strategies: (1) Use human-provided answers to prompts to tune the model with supervised training. (2) Collect comparison data to train a reward model and then use this reward model to tune GPT-3 with reinforcement learning from human feedback (RLHF). - Result: InstructGPT shows better truthfulness and less bias, i.e., better alignment. | GPT-3 :GPT-3的训练主要基于Common Crawl。 数据为中心的人工智能策略 : (1) 训练一个分类器 ,通过每个文档与高质量文档的相似性来 过滤掉低质量文档 (以WebText作为高质量文档的代理); (2)使用Spark的 MinHashLSH模糊去重文档 ; (3)通过添加WebText、图书语料库和维基百科来增加数据。 结果 :在45TB的纯文本中,通过质量筛选仅选择了1.27%的数据,筛选后获得了570GB的文本。GPT-3在零样本设置下明显优于GPT-2。 InstructGPT :让 人类评估答案 ,以调整GPT-3,使其更好地符合人类的预期。他们为注释者设计了测试,只有通过测试的人才有资格进行注释。他们甚至设计了一份调查问卷,以确保注释者享受注释过程。 数据为中心的人工智能策略 : (1)使用 人为提供的问题答案 对模型进行有监督训练; (2)收集 比较数据 ,训练一个奖励模型,然后使用这个奖励模型通过从人类反馈中进行强化学习(RLHF)来调整GPT-3。 结果 :InstructGPT展示出 更好的真实性和较少的偏见 ,即更好的对齐。 |
| ChatGPT/GPT-4: The details are not disclosed by OpenAI. But it is known that ChatGPT/GPT-4 largely follow the design of previous GPT models, and they still use RLHF to tune models (with potentially more and higher quality data/labels). It is commonly believed that GPT-4 used an even larger dataset, as the model weights have been increased. | ChatGPT/GPT-4 :OpenAI并没有披露详细信息。但众所周知,ChatGPT/GPT-4在很大程度上遵循了之前GPT模型的设计,并且仍然使用RLHF来调整模型(可能使用了更多和更高质量的数据/标签)。普遍认为,GPT-4 使用了更大的数据集 ,因为 模型的权重已经增加 。 |
| Inference data development. As recent GPT models are already sufficiently powerful, we can achieve various goals by tuning prompts (or tuning inference data) with the model fixed. For example, we can conduct text summarization by offering the text to be summarized alongside an instruction like “summarize it” or “TL;DR” to steer the inference process. Designing the proper prompts for inference is a challenging task. It heavily relies on heuristics. A nice survey has summarized different promoting methods. Sometimes, even semantically similar prompts can have very diverse outputs. In this case, Soft Prompt-Based Calibration may be required to reduce variance. | 推理数据开发。由于最新的GPT模型已经非常强大,我们可以通过固定模型并调整提示(或推理数据)来实现各种目标。例如,我们可以通过提 供要摘要的文本以 及诸如“总结一下”或“TL;DR”之类的指示来进行文本摘要。 设计适当的推理提示 是一项具有挑战性的任务。它在很大程度上依赖于启发式方法。一份很好的调查总结了不同的推理方法。有时,即使语义上相似的提示也可能有非常不同的输出。在这种情况下,可能 需要使用软提示校准来减少方差 。 |
提示调优

基于软提示的校准
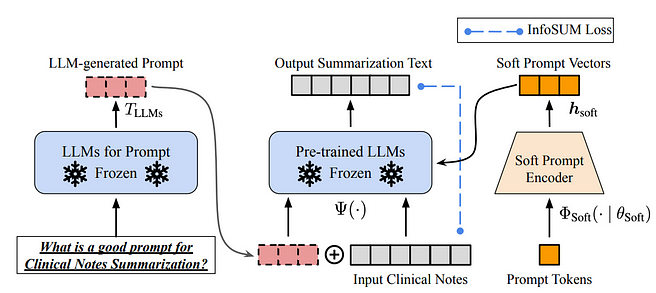
| The research of inference data development for LLMs is still in its early stage. More inference data development techniques that have been used in other tasks could be applied in LLMs in the near future. Data maintenance. ChatGPT/GPT-4, as a commercial product, is not only trained once but rather is updated continuously and maintained. Clearly, we can’t know how data maintenance is executed outside of OpenAI. So, we discuss some general data-centric AI strategies that are or will be very likely used for GPT models: - Continuous data collection: When we use ChatGPT/GPT-4, our prompts/feedback could be, in turn, used by OpenAI to further advance their models. Quality metrics and assurance strategies may have been designed and implemented to collect high-quality data in this process. - Data understanding tools: Various tools could have been developed to visualize and comprehend user data, facilitating a better understanding of users’ requirements and guiding the direction of future improvements. - Efficient data processing: As the number of users of ChatGPT/GPT-4 grows rapidly, an efficient data administration system is required to enable fast data acquisition. | LLM的推理数据开发研究仍处于早期阶段。将来可能会将在其他任务中使用的更多推理数据开发技术应用于LLM。 数据维护。作为一款商业产品,ChatGPT/GPT-4不仅仅是进行一次训练,而是持续不断地进行更新和维护。显然,我们无法得知OpenAI之外如何执行数据维护。因此,我们讨论了一些常见的数据为中心的人工智能策略,这些策略在GPT模型中已经或将很可能被使用: 持续数据收集 :当我们使用ChatGPT/GPT-4时,我们的 提示/反馈 可能被OpenAI用于 进一步改进 他们的模型。可能已经设计和实施了质量指标和保证策略,以在这个过程中收集高质量的数据。 数据理解工具 :可能已经开发了各种工具 来可视化和理解用户数据 ,促进对用户需求的更好理解,并指导未来改进的方向。 高效数据处理 :随着ChatGPT/GPT-4用户数量的迅速增长, 需要一个高效的数据管理系统 ,以实现快速的数据获取。 |
|---|
数据科学社区可以从这一波LLM(语言模型)中学到什么?——工程化数据将成为改进LLM的关键、LLM将实现更好的数据中心的AI解决方案
What Can the Data Science Community Learn from this Wave of LLMs?
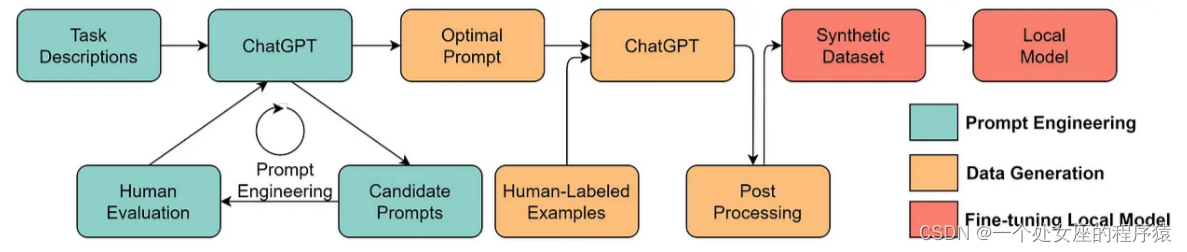
| The success of LLMs has revolutionized AI. Looking forward, LLMs could further revolutionize the data science lifecycle. We make two predictions: Data-centric AI becomes even more important. After years of research, the model design is already very mature, especially after Transformer. Engineering data becomes a crucial (or possibly the only) way to improve AI systems in the future. Also, when the model becomes sufficiently powerful, we don’t need to train models in our daily work. Instead, we only need to design the proper inference data (prompt engineering) to probe knowledge from the model. Thus, the research and development of data-centric AI will drive future advancements. LLMs will enable better data-centric AI solutions. Many of the tedious data science works could be performed much more efficiently with the help of LLMs. For example, ChaGPT/GPT-4 can already write workable codes to process and clean data. Additionally, LLMs can even be used to create data for training. For example, recent work has shown that generating synthetic data with LLMs can boost model performance in clinical text mining. | LLM的成功 彻底改变了人工智能领域 。展望未来,LLM可能进一步革新数据科学生命周期。我们提出两个预测: 数据为中心的人工智能变得更加重要 。经过多年的研究,模型设计已经非常成熟,特别是在Transformer之后。 工程化数据 将成为未来改进人工智能系统的 关键 (或可能是唯一)途径。此外,当模型变得足够强大时,我们在日常工作中 就不再需要训练模型 。相反,我们 只需要设计适当的推理数 据(即提示工程)来从模型中获取知识。因此,数据为中心的人工智能的研究和发展将推动未来的进步。 LLM将使数据为中心的人工智能解决方案更加优秀 。借助LLM的帮助,许多繁琐的数据科学工作可以更高效地完成。例如,ChaGPT/GPT-4已经可以编写可用的代码来处理和清洗数据。此外,LLM甚至 可以用于创建用于训练的数据 。例如,最近的研究表明,使用LLM生成合成数据可以提升临床文本挖掘模型的性能。 |
|---|
用LLM生成合成数据来训练模型
Resources
| I hope this article can inspire you in your own work. You can learn more about the data-centric AI framework and how it benefits LLMs in the following papers: [1] Data-centric Artificial Intelligence: A Survey [2] Data-centric AI: Perspectives and Challenges We have maintained a GitHub repo, which will regularly update the relevant data-centric AI resources. Stay tuned! In the later articles, I will delve into the three goals of data-centric AI (training data development, inference data development, and data maintenance) and introduce the representative methods. | 希望这篇文章能激发您在自己的工作中的灵感。您可以通过以下论文进一步了解数据为中心的人工智能框架以及它对LLM的好处: [1] 《数据为中心的人工智能:一项调查》 [2] 《数据为中心的人工智能:观点与挑战》 我们维护了一个GitHub仓库,将定期更新相关的数据为中心的人工智能资源。敬请关注! 在后续的文章中,我将深入探讨数据为中心的人工智能的三个目标(训练数据开发、推理数据开发和数据维护),并介绍代表性的方法。 |
|---|